What Are AWS Data Storage Services, and Which is Right For You?
Knowing the details of AWS data storage service offerings will help you make smart decisions for storing your data.

In my previous blog post, I provided a basic explanation of storage technology, delving into the differences between block and object storage. Both of these approaches play into the AWS service offerings. This blog post will cover the details of the storage services offered by AWS.
AWS Data Storage Service Offerings
AWS currently offers the following storage services:
- Instance/Ephemeral Storage
- Elastic Block Storage (EBS)
- Elastic File System (EFS)
- S3 (Simple Storage Service) ecosystem along with Glacier
The first three items in the list above — ephemeral storage, elastic block storage and elastic file system — are different abstractions around block storage. These three offer Portable Operating System Interface (POSIX) compliances. The last item in the list, S3 ecosystem, is centered around the object storage. The end use cases dictate the optimal storage service to be used in different scenarios.
What is Ephemeral Storage (Instance Storage)?
Each EC2 guest instance (or container) can use the disk storage attached to the physical host. When an EC2 instance/container is launched, a mount point can be created in the Guest VM and mounted to a portion of the disk from the underlying host. Since the storage is local to the host, there is no network I/O overhead for reading or updating the content. As a result, the disk access is extremely fast, setting aside the constraints of the physical media. Furthermore, there is no charge associated with the ephemeral storage.
Content stored in ephemeral storage survives reboots, however, when an EC2 instance is stopped, terminated or restarted, all the content stored in the instance storage is lost. One of the characteristics of the AWS infrastructure is that when an EC2 instance is stopped and restarted, the underlying host will always change.
As a result, the original mount point of the ephemeral disk would not be available in the new host. Instance disk storage can be used as a scratch pad for storing temporary objects, for example, while transforming original objects to a new format (to be stored in an EBS volume and/or S3). However, the applications created using ephemeral disk must be resilient in order to recover from failures when there is a change in the underlying host.
EFS vs. EBS: What is Elastic Block Storage (EBS Storage)?
Elastic Block Storage provides another type of storage abstraction and is one of the most popular storage services providing persistent data storage. Data stored in an EBS volume is retained even when the EC2 instance as well as the underlying physical host is restarted (stop and start), rebooted or terminated.
One of the core principles of designing robust, highly available applications is to decouple compute from storage. This decoupling allows you to attach the same volume to different EC2 instances (one at time). Multiple EBS volumes can also be attached to the same EC2 instance. Storing data to a separate volume (instead of the root volume) makes the backup and restoration easier and reduces the footprint of the backup storage — as an EC2 instance with a root volume can easily be created via an Amazon Machine Image (AMI) pipeline within a few minutes.
Due to security concerns, a well-architected cloud framework recommends rebuilding the EC2 instances/root volumes at a regular interval, say every 30 to 45 days or so, to ensure that the latest security patches are applied to the instances. Creating a fresh install may also help to stop a data breach from a previously breached instance — if an attacker managed to install malware in an earlier instance.
Once allocated, EBS volumes will continue to incur charges regardless of whether any data is stored in the EBS volume. The storage cost depends on the EBS volume type and size. This is different than for S3 — where the customer is required to pay only for the size used by the object. There are a set of APIs that allow you to adjust various properties of an EBS volume such as changing the volume type and resizing EBS volumes. Increasing the size of an EBS volume is straightforward and consists of invoking an AWS API to specify the new larger disk size and executing the resize command (for Linux, there is a different command for Windows) as a privileged user from the guest OS. Reducing the EBS volume size can be a bit tricky and may consist of creating a new volume and copying data over to the new volume and deleting the old volume.
It is possible to detach EBS volumes from one instance and reattach to another instance. This may be required, for example, for fixing the Secure Shell (SSH) keys associated with an instance or some problems with the Sudoers file. However, EBS volumes can only be attached to one instance at any given time. The most common use cases for EBS include root volume for installing OS and associated applications and data volume. For a data analytics platform, there can be a whole bunch of EBS volumes attached to a given EC2 instance. As stated earlier, this separation of root and data volumes allows the user to detach data volume from existing instance and reattach to another EC2 instance in case there are problems with the original EC2 instance or the instance required vertical scaling due to increased workload.
EFS vs. EBS: What is Elastic File Storage (EFS Storage)?
EFS is equivalent to the network file system- (NFS) based storage available in AWS. The data can be physically stored in a variety of network drives centrally. EC2 instances requiring access can mount the network drive via NFS client software. Data stored in an EFS volume can be mounted by a number of EC2 instances and accessed simultaneously. Some use cases of EFS include sharing a common file across multiple users and creating a common home directory across all the EC2 instances in the fleet.
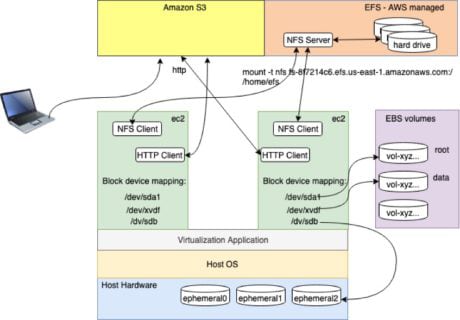
Different Storage Options Available Within AWS — Click to Enlarge Image
Simple Storage Service (S3)
S3 was one of the first services created by AWS. S3 provides a highly scalable, redundant, highly durable and available storage service. Even though the name has “simple” in it, S3 is anything but simple — there are amazing types of additional features and services centered around S3. S3 is an object-based, API-driven storage service. S3 is different than the three other storage types we have discussed in that the objects stored in S3 do not support POSIX attributes.
The original intent of S3 was to make it very easy for end users to create a highly scalable static web page. The users can simply upload their content (such as images or HTML files) to an S3 bucket and make it available via a URL without having to worry about creating a web/application server, load balancers, redundancy, etc., and without requiring programming expertise.
Objects in S3 buckets are automatically assigned a URL. Hence, the bucket name chosen must be unique globally. Choosing a name that has not been used by any other users in the S3 namespace is mandatory. AWS is positioning S3 as one of the most critical and fundamental components within its infrastructure and plays a pivotal role in most of its solution offerings.
As an example, consider the creation of data lakes for an analytics platform. The reference architecture of AWS leverages S3 as the object store for storing original/untransformed incoming data and then creating additional domain-specific S3 buckets with content derived from the original source via use case-specific Extract-Transform-Load (ETL/ELT) process. The content of the original S3 bucket will never be updated and can be used to replay scenarios if problems are encountered during later ETL phases.
Furthermore, other services from AWS such as Redshift, EMR, Glue Catalog and Spectrum provide a scalable mechanism for reading contents from an S3 bucket very quickly and run analytics on the S3 data set. Execution of these workflows is possible without getting bogged down in creating clusters. Another example would be the creation of AMIs for spinning of application-specific EC2 instances and EBS volume snapshots for backup purposes. The more we look into the AWS infrastructure, the more we will find this as a way of integrating any new services with S3.
Navigating Cloud Storage Services
In this blog, I have just scratched the surface by providing a quick high-level overview of the storage services available within the AWS infrastructure. AWS has done great innovation in this space. I will be covering some of these details in subsequent postings.
As stated earlier, the creation of services in the cloud space requires a thorough understanding of the underlying infrastructure services and end user scenarios to come up with a cost-optimized, balanced architecture with suitable tradeoffs given to various solution constraints. CDW Professional Services can assist your organization in this journey by laying a solid foundation on which additional services can be developed.
